目录人工智能数学基础pdf 人工智能数学基础唐宇迪答案 人工智能的矩阵代数方法pdf 人工智能数学基础课后题答案 人工智能数学基础pdf唐宇迪
姓名:洪涛 学号:16020188030
【嵌牛导读】: 概率论是人工智能研究中必备的数学基础,在进行人工智能研究是必不可少数学概率论的有关知识。
【嵌牛鼻子】:人工智能,数学概率论
【嵌牛提问】:人工智能相关的数学概率论有哪些?
【嵌牛正文】:
概率论(probability theory)也是人工智能研究中必备的数学基础。随着连接主义学派的兴起,概率统计已经取代了数理逻辑,成为人工智能研究的主流。
同线性代数一样,概率论也代表了一种看待世界的方式,其关注的焦点是无处不在的可能性。对随机事件发生的可能性进行规范的数学描述就是概率论的公理化过程。概率的公理化结构体现出的是对概率本质的一种认识。
将同一枚硬币抛掷 10 次,其正面朝上的次数既可能一次没有,也可能全部都是,换算成频率就分别对应着 0% 和 100%。频率本身显然会随机波动,但随着重复试验的次数不断增加,特定事件出现的频率值就会呈现出稳定性,逐渐趋近于某个常数。
从事件发生的频率认识概率的方法被称为“频率学派”(frequentist probability),频率学派口中的“概率”,其实是一个可独立重复的随机实验中单个结果出现频率的极限。因为稳定的频率是统计规律性的体现,因而通过大量的独立重复试验计算频率,并用它来表征事件发生的可能性是一种合理的思路。
在概率的定量计算上,频率学派依赖的基础是古典概率模型。在古典概率模型中,试验的结果只包含有限个基本事件,且每个基本事件发生的可能性相同。假设所有基本事件的数目为 n,待观察的随机事件 A 中包含的基本事件数目为 k,则古典概率模型下事件概率的计算公式为:
从这个基本公式就可以推导出复杂的随机事件的概率。
前文中的概率定义针对都是单个随机事件,可如果要刻画两个随机事件之间的关系,这就需要引入条件概率的概念。
条件概率(conditional probability)是根据已有信息对样本空间进行调整后得到的新的概率分布。假定有两个随机事件 A和B,条件概率就是指事件 A 在事件 B已经发生的条件下发生的概率,用以下公式表示:
上式中的P(AB)称为联合概率(joint probability),表示的是 A和B 两个事件共同发生的概率。如果联合概率等于两个事件各自概率的乘积,即P(AB)=P(A)⋅P(B),说明这两个事件的发生互不影响,即两者相互独立。对于相互独立的事件,条件概率就是自身的概率,即P(A|B)=P(A)。
基于条件概率可以得出全概率公式(law of total probability)。全概率公式的作用在于将复杂事件的概率求解转化为在不同情况下发生的简单事件的概率求和,即:
全概率公式代表了频率学派解决概率问题的思路,即先做出一些假设(P(Bi)),再在这些假设下讨论随机事件的概率(P(A|Bi))。
对全概率公式 进行整理,就演化出了求解“逆概率”问题。所谓“逆概率”解决的是在事件结果已经确定的条件下(P(A)),推断各种假设发生的可能性(P(Bi|A))。其通用的公式形式被称为贝叶斯公式:
从科学研究的方法论来看,贝叶斯定理提供了一种全新的逻辑。它根据观测结果寻找合理的假设,或者说根据观测数据寻找最佳的理论解释,其关注的焦点在于后验概率。概率论的贝叶斯学派(Bayesian probability)正是诞生于这种理念。
在贝叶斯学派眼中,概率描述的是随机事件的可信程度。
频率学派认为假设是客观存在且不会改变的,即存在固定的先验分布。因而在计算具体事件的概率时,要先确定概率分布的类型和参数,以此为基础进行概率推演。
相比之下,贝叶斯学派则认为固定的先验分布是不存在的,参数本身也是随机数。换句话说,假设本身取决于观察结果,是不确定并且可以修正的。数据的作用就是对假设做出不断的修正,使观察者对概率的主观认识更加接近客观实际。
概率论是线性代数之外,人工智能的另一个理论基础,多数机器学习模型采用的都是基于概率论的方法。但由于实际任务中可供使用的训练数据有限,因而需要对概率分布的参数进行估计,这也是机器学习的核心任务。
概率的估计有两种方法:最大似然估计法(maximum likelihood estimation)和最大后验概率法(maximum a posteriori estimation),两者分别体现出频率学派和贝叶斯学派对概率的理解方式。
最大似然估计法的思想是使训练数据出现的概率最大化,依此确定概率分布中的未知参数,估计出的概率分布也就最符合训练数据的分布。最大后验概率法的思想则是根据训练数据和已知的其他条件,使未知参数出现的可能性最大化,并选取最可能的未知参数取值作为估计值。在估计参数时,最大似然估计法只需要使用训练数据,最大后验概率法除了数据外还需要额外的信息,就是贝叶斯公式中的先验概率。
具体到人工智能这一应用领域,基于贝叶斯定理的各种方法与人类的认知机制吻合度更高,在机器学习等领域中也扮演着更加重要的角色。
概率论的一个重要应用是描述随机变量(random variable)。根据取值空间的不同,随机变量可以分成两类:离散型随机变量(discrete random variable)和连续型随机变量(continuous random variable)。在实际应用中,需要对随机变量的每个可能取值的概率进行描述。
离散变量的每个可能的取值都具有大于 0 的概率,取值和概率之间一一对应的关系就是离散型随机变量的分布律,也叫概率质量函数(probability mass function)。概率质量函数在连续型随机变量上的对应就是概率密度函数(probability density function)。
概率密度函数体现的并非连续型随机变量的真实概率,而是不同取值可能性之间的相对关系。对连续型随机变量来说,其可能取值的数目为不可列无限个,当归一化的概率被分配到这无限个点上时,每个点的概率都是个无穷小量,取极限的话就等于零。而概率密度函数的作用就是对这些无穷小量加以区分。虽然在x→∞时,1/x和 2/x 都是无穷小量,但后者永远是前者的 2 倍。这类相对意义而非绝对意义上的差别就可以被概率密度函数所刻画。对概率密度函数进行积分,得到的才是连续型随机变量的取值落在某个区间内的概率。
定义了概率质量函数与概率密度函数后,就可以给出一些重要分布的特性。重要的离散分布包括两点分布、二项分布和泊松分布,重要的连续分布则包括均匀分布、指数分布和正态分布。
两点分布(Bernoulli distribution):适用于随机试验的结果是二进制的情形,事件发生 / 不发生的概率分别为 p/(1−p)。任何只有两个结果的随机试验都可以用两点分布描述,抛掷一次硬币的结果就可以视为等概率的两点分布。
二项分布(Binomial distribution):将满足参数为 p的两点分布的随机试验独立重复 n次,事件发生的次数即满足参数为(n,p)的二项分布。二项分布的表达式为:
泊松分布(Poisson distribution):放射性物质在规定时间内释放出的粒子数所满足的分布,参数为 λ的泊松分布表达式为
当二项分布中的n很大且pp很小时,其概率值可以由参数为λ=np的泊松分布的概率值近似。
均匀分布(uniform distribution):在区间 (a,b) 上满足均匀分布的连续型随机变量,其概率密度函数为 1/(b−a),这个变量落在区间(a,b)内任意等长度的子区间内的可能性是相同的。
指数分布(exponential distribution):满足参数为θ指数分布的随机变量只能取正值,其概率密度函数为
指数分布的一个重要特征是无记忆性:即 P(X>s+t|X>s)=P(X>t)。
正态分布(normal distribution):参数为正态分布的概率密度函数为:
当 μ=0,σ=1 时,上式称为标准正态分布。正态分布是最常见最重要的一种分布,自然界中的很多现象都近似地服从正态分布。
除了概率质量函数 / 概率密度函数之外,另一类描述随机变量的参数是其数字特征。数字特征是用于刻画随机变量某些特性的常数,包括数学期望(expected value)、方差(variance)和协方差(covariance)。
数学期望即均值,体现的是随机变量可能取值的加权平均,即根据每个取值出现的概率描述作为一个整体的随机变量的规律。方差表示的则是随机变量的取值与其数学期望的偏离程度。方差较小意味着随机变量的取值集中在数学期望附近,方差较大则意味着随机变量的取值比较分散。
数学期望和方差描述的都是单个随机变量的数字特征,如果要描述两个随机变量之间的相互关系,就需要用到协方差和相关系数。协方差度量了两个随机变量之间的线性相关性,即变量 Y能否表示成以另一个变量 X 为自变量的 aX+b的形式。
根据协方差可以进一步求出相关系数(correlation coefficient),相关系数是一个绝对值不大于 1 的常数,它等于 1 意味着两个随机变量满足完全正相关,等于 -1 意味着两者满足完全负相关,等于 0 则意味着两者不相关。无论是协方差还是相关系数,刻画的都是线性相关的关系。如果随机变量之间的关系满足 Y=X2,这样的非线性相关性就超出了协方差的表达能力。

人工智能包括五大核心技术:
1.计算机视觉:计算机视觉技术运用由图像处理操作及机器学习等技术所组成的序列来将图像分析任务分解为便于管理的小块任务。
2.机器学习:机器学习是从数据中自动发现模式,模式一旦被发现便可以做预测,处理的数据越多,预测也会越准确仿薯。
3.自然语言处理:对自然语言文本的处理是指计算机拥有的与人类类似的对文本进行处理的能力。例如自动识别文档中被提及的人物、地点等,或将合同中的条款提取出来制作成表。
4.机器人技术:近年来,随备咐者着算法等核心技术提升,机器人取得重要突破。例简庆如无人机、家务机器人、医疗机器人等。
5.生物识别技术:生物识别可融合计算机、光学、声学、生物传感器、生物统计学,利用人体固有的生体特性如指纹、人脸、虹膜、静脉、声音、步态等进行个人身份鉴定,最初运用于司法鉴定。

需要扎实的数学基础。
为什么学习人工智能这么看重数学基础呢?
这个首先得从目前人工智能的本质说起,目前以神经网络为基础的深度学习体系,其实可以看做是一个线性代数矩阵模型,从微观上来说是微分方程。
人工智能的重点在于智能,而智能的最终体现应该是随机性,比如你永远不知道一个独立的智慧生命在下一秒会做什么事情。
数学是有解可计算的,智能是无解无法预测的,但智能的很多行为又是可以数学进行计算的,所以智能与数学之间应该是具有强关系但并非唯一相关。
这也是为什么国内外大多数研究所招实习生首先看重的就是数学能力。
学人工智能要求怎样的数学基础
“线性代数”、“概率论”、“优化论”这三门数学课程,前两门是建模,后一门是求解,是学习人工智能的基础。(你们要的我都有)
1.线性代数
线性代数是学习人工智能过程中必须掌握的知识。线性代数中我们最熟悉的就是联立方程式了,而线性代数的起源就是为了求解联立方程式。只是随着研究的深入,人们发现它还有更广阔的用途。
2.概率论
“概率统计”是统计学习中重要的基础课程,因为机器学习很多时候就是在处理事务的不确定性。
3.优化
模型建立起来后,如何求解这个模型属于优化的范畴。优化,就是在无法获得问题的解析解的时候,退而求其次找到一个最优解。当然,需要提前定义好什么是最优,就好像篮球比赛之前得先定义好比赛规则一样。
通常的做法是想办法构造一个损失函数,然后找到损失函数的最小值进行求解。
人工智能训练师培训课程如下:
1、机器学习中的Python
Python环境搭建与其基础语法的学习;熟悉列表元组等基础概念与python函数的形式;Python的IO操作;Python中类的使用介绍;python使用实例讲解机器学习领域的经典算法、模型及实现的任务等。
2、人工智能数学基础
熟悉数学中的符号表示;理解函数求导以及链式求导法则;理解数学中函数的概念;熟悉矩阵相关概念以及数学表示。
3、机器学习概念与入门
了解人工智能中涉及到的相关概羡燃念;了解如何获取数据以及特征工程;熟悉数据预处理方法;理解模型训练过程;熟悉pandas的使用;解可视化过程;Panda使用讲解;图形绘制。
4、机器学习的数学基础—数学分析
掌握和了解人工智能技术底层数学理论支撑;概率论,矩阵和凸优化的介绍,相应算法设计和原理;凸优化理论,流优化手段SGD,牛顿法等优化方法。
5、深度学习框架TensorFlow
了解及学习变量作用域与变量命名;搭建多层神经网络并完成优化。
人工智能训练师的工作任务
1、标注和加工图片、文字、语音等业务的原始数据;
2、分析提炼专业领域特征,训练和评测人工智能产品相关算法、功能和性能;
3、设计人工智能产品的交互流程和应用胡液解决裤派物方案;
4、监控、分析、管理人工智能产品应用数据;
5、调整、优化人工智能产品参数和配置。
首先,你需要学一门适合人工智能的语言并学习其基础知识(如Python、R),推荐选择Python,下文我会说明Python怎么学习人工智能。
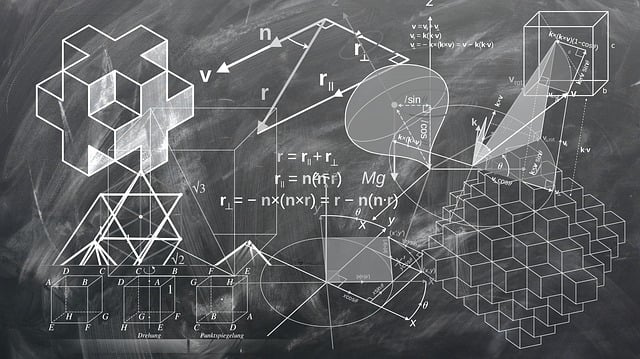
人工智能的本质是数学。如果你想真正透彻理仿好解人工智能算法原理的话,你需要学习高等数学,具体内容如下图:
人工智能数学基础
如果你选择了Python,还需要学习一下人工智能所需要的第三方库(Pandas、Numpy、openCV、Matplotlib等),Pandas、Numpy是数据处理的,openCV是图像处理的,Matplotlib是画图的。
以上是人工智能的基础,下文将阐述人工智能学习路线:
一.机器学习:
你需要学习一下机器学习的经典算法(如线性回归、逻辑回归、KNN、K-Means等)以及一些机器学习的第三方库,如scikit-learn.
练习。练习是巩固所学知识的一个重要方法。可以在Kaggle上参加一些新手比赛侍册,如著名的泰坦尼克号乘客生存率预测。
二.深度学习:
购买显卡。深度学习的学习对显卡的要求比较高,因此一张不错的显卡是十分必要的。而且注备谈铅意要买英伟达的显卡,也就是N卡。因为一些深度学习的框架(特别是tensorflow)只能在英伟达的显卡上跑,目前推荐购买RTX2070,性价比较高。买别的也可以,但是显存最好大于等于6G。
在深度学习的学习中,你将接触一个新的概念——神经元网络。你需要学习一些神经网络的经典神经网络,如CNN、RNN。还有一些由它们衍生出来的神经网络结构,如YOLO。
其次,你需要学习至少一个深度学习库,如tensorflow(常用于工业开发)、pytorch(适合用于研究)。
练习。练习是巩固所学知识的一个重要方法。可以在Kaggle上参加一些正式比赛,也就是有奖金的比赛来提高自己的水平。